Daten sind in Unternehmen ein wertvolles Gut. Aber sie sind nur dann nützlich, wenn:
- Sie müssen verfügbar sein.
- Sie müssen verständlich sein.
- Sie müssen aktuell sein.
Viele Auswertungen werden auch nur einmals benötigt, dabei lohnt es sich nicht große Auswertungen zu beauftragen.
Das ist wo KLAUS ins Spiel kommt, aber bevor wir näher auf ihn eingehen nehmen wir euch mit auf eine Reise, wie er entwickelt wurde.
Neue Möglichkeiten durch LLMs
Das eigentliche Problem liegt in der Übersetzung der Semantik von menschlicher Sprache in einer Fachdomain in SQL-Abfragen und deren Auswertung. In vielen Bereichen werden in dieser Domäne bereits LLMs verwendet. Warum nicht auch hier?
Wäre es Möglich eine SQL-Datenbank mit einem LLM zu verbinden? Dann wäre es Möglich direkt Fragen an die eigenen Daten zu schicken.
Es gab jedoch einige Probleme:
- Die Metadaten der Datenbank (Namen der Tabellen und Spalten) sind als Erklärung unzureichend.
- Die Geschwindigkeit ist nicht sehr hoch.
- Einige Datentypen benötigen eine Erklärung
- Jeder Benutzer kann auf alle Daten zugreifen
- Abhängigkeit von Claude und damit der Cloud
Entwicklung einer Lösung
Dazu haben wir einen ChatBot konzipiert, der die Sprache des Nutzers und die Fachdomäne versteht. Er generiert selbstständig gültige T-SQL-Abfragen, führt diese aus und stellt die Ergebnisse in natürlicher Sprache sowie als Diagramme dar. Ein zentraler Bestandteil des Projekts war die Evaluation, ob und welche lokalen Modelle sich dafür eignen.
LLM-Modelle
Die Cloud-Modelle lieferten durchgehend sehr gute Ergebnisse, was erwartet war. Auch lokal zeigten sich einige Modelle wie das OSS 20B von OpenAI oder das Mistral 7B als gut einsetzbar. Das OSS 120B von OpenAI wirkte zwar vielversprechend, ließ sich jedoch aufgrund von Performance-Einschränkungen (Geschwindigkeit, Kontextfenster) nicht optimal auf der Hardware betreiben.
Google Gemma 3 konnte lokal nicht genutzt werden, da es nicht für die Tool-Verwendung (bzw. die spezifische Anbindung) trainiert war.

KLAUS
Ein Chatbot, welcher aus Fragen Ergebnisse und Diagramme ableiten kann.

Metadata
Damit ein LLM hochwertige Auswertungen erstellen kann, benötigt es zusätzliche Metadaten. Da EF Core bereits C#-Klassen (POCOs) nutzt, um Datenbanktabellen abzubilden, bietet es sich an, diese Klassen um LLM-spezifische Metadaten zu erweitern. So bleiben die C#-Klassen die zentrale Single Source of Truth.
Wir setzen zwei benutzerdefinierte Attribute ein:
- LlmExplanation: Beschreibt Tabelle, Spalte oder Wert (z. B. für Fachbegriffe oder Berechnungslogik).
- LlmIgnore: Markiert Spalten, die für das LLM irrelevant sind und ausgeblendet werden sollen.
EF Core mappt C#-Properties standardmäßig auf Datenbankspalten. Computed Properties (berechnete Eigenschaften) existieren jedoch nur im Code und nicht in der Datenbank. Dennoch sind sie oft geschäftsrelevant und sollten dem LLM zugänglich sein. Dafür muss dem LLM explizit mitgeteilt werden, wie sich diese Properties aus den physischen Spalten berechnen lassen.

Ein Beispiel
[LlmExplanation(@"Article is a sample if Number starts with 'S-'.
Default name is NameInGerman.
Articles are sold in boxes; items = boxes * UnitsPerPackage.")]
public class Article
{
public string Number { get; set; }
public string NameInGerman { get; set; }
[LlmExplanation("Number of individual items per package/box")]
public decimal UnitsPerPackage { get; set; }
}
Die Werkzeuge
Die Tools im Überblick:

Dem LLM müssen wir in der Systemprompt noch mitteilen, was wir wollen, wie es Umzusetzen ist und welche Tools es dafür zur Verfügung hat. Dort teilen wir mit, wer das LLM ist, wer wir sind, was wir wollen, und wie das LLM das Umsetzen kann.

Kurz zusammengefasst: Systemüberblick bis jetzt.
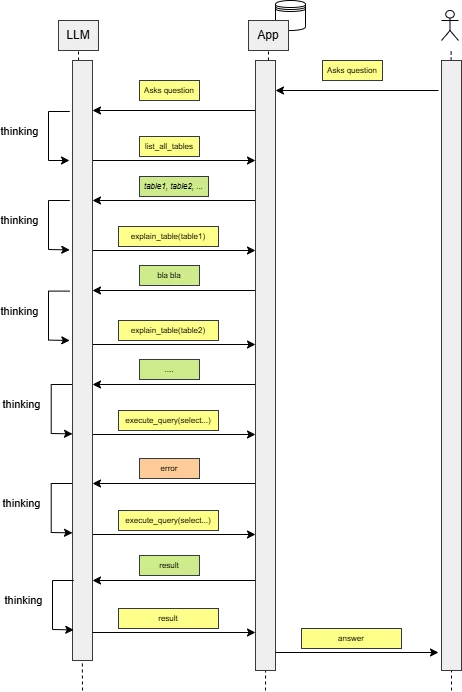
Die ersten Ergebnisse
Mit diesem ersten Aufbau ließen sich bereits brauchbare Ergebnisse erzielen. Das LLM konnte relevante Tabellen identifizieren, zusätzliche Metadaten gezielt nachladen, daraus gültige T-SQL-Abfragen erzeugen und die Resultate als Text oder Diagramm aufbereiten. Damit war grundsätzlich gezeigt, dass natürlichsprachliche BI-Abfragen auf dieser Basis funktionieren können.
Gleichzeitig wurden aber auch die Grenzen des Ansatzes deutlich. Jeder Durchlauf war noch relativ teuer, weil das System die benötigten Tabellen, Metadaten und Query-Schritte immer wieder neu herleiten musste. Selbst bei sehr ähnlichen oder identischen Fragestellungen begann der Prozess praktisch jedes Mal von vorne. Das kostet Zeit, verbraucht Kontextfenster und erhöht die Wahrscheinlichkeit, dass sich das Modell bei längeren Ableitungsketten unnötig verrennt.
Das zentrale Problem war also nicht mehr, ob der Ansatz grundsätzlich funktioniert, sondern wie sich erfolgreiche Abfragemuster wiederverwenden lassen. Genau an dieser Stelle setzen die nächsten Optimierungen an.
Optimierungen
RAG
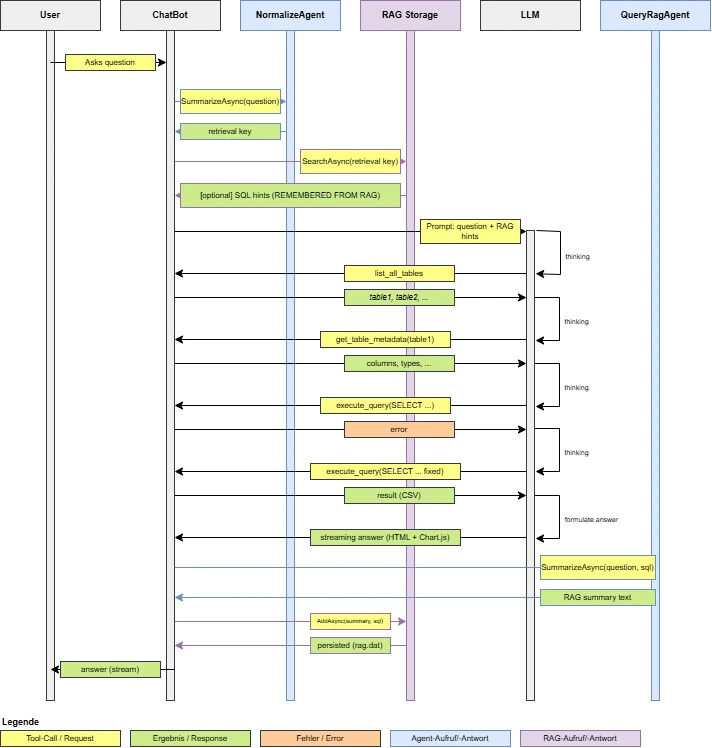
Damit das System nicht bei jeder ähnlichen Frage wieder bei null beginnen muss, speichern wir erfolgreiche Abfragen in einem RAG-Speicher ab. RAG steht für Retrieval Augmented Generation. Gemeint ist damit, dass das LLM vor der eigentlichen Antwort zusätzliche, bereits bekannte Informationen aus einem Speicher abrufen kann.
In unserem Fall sind das keine beliebigen Textdokumente, sondern bewährte SQL-Muster. Sobald KLAUS zu einer Benutzerfrage eine gültige Query erzeugt und tatsächlich ausgeführt hat, wird diese Abfrage zusammen mit einer fachlichen Kurzbeschreibung im Speicher abgelegt. Diese Beschreibung enthält nicht die exakten Eingabewerte des Benutzers, sondern den verallgemeinerten analytischen Intent, zum Beispiel welche Kennzahl gesucht wurde, welche Gruppierung relevant war und welche Filter oder Zeiträume eine Rolle gespielt haben.
Technisch verwenden wir dafür einen Vektor-Speicher. Die textuelle Beschreibung einer erfolgreichen Query wird in ein Embedding umgewandelt, also in einen Zahlenvektor, der die semantische Bedeutung des Textes abbildet. Stellt ein Benutzer später eine ähnliche Frage, wird auch diese Frage in eine verallgemeinerte Form gebracht und als Embedding dargestellt. Anschließend wird nicht nach exaktem Wortlaut gesucht, sondern nach semantischer Ähnlichkeit. Dadurch können auch Fragen wiedergefunden werden, die anders formuliert sind, aber fachlich dasselbe meinen.
Der Vorteil ist zweifach. Zum einen wird das System schneller, weil ähnliche Fragestellungen nicht jedes Mal vollständig neu hergeleitet werden müssen. Zum anderen steigt die Qualität, weil bereits erfolgreiche Query-Muster wiederverwendet werden können. KLAUS lernt also nicht durch klassisches Training nach, sondern über einen kontrollierten, nachvollziehbaren Wissensspeicher erfolgreicher Abfragen.
Die Agenten kommen
Nachdem die RAG-Basis stand, haben wir den Ablauf in spezialisierte Agenten aufgeteilt. Das Ziel war eine klarere Verantwortlichkeit pro Schritt, weniger Kontextballast pro Modellaufruf und bessere Wiederverwendbarkeit im Gesamtsystem.

Oder hier in kurz, wie die Agenten zusammenarbeiten:
- Das Hauptmodell beantwortet die Frage über SQL-Tool-Calls.
- Antwort (Text/Diagramm) wird an den Benutzer gestreamt.